
A History of Version Control
Discover the predecessors of modern distributed version control systems like Git

T
I am a Unity C# developer, educator, and writer from Canada.
Search for a command to run...
Discover the predecessors of modern distributed version control systems like Git
I am a Unity C# developer, educator, and writer from Canada.
No comments yet. Be the first to comment.
Introduction 👋 Hi, I’m Taryn! I’m a Unity dev who created a small project for Hacktoberfest 2023. In this devlog, I’ll introduce you to the project and talk about my goals for Hacktoberfest as a game developer. Tiny Troves of Dev Wisdom First, let’...

In today's post, I'll be talking about my latest Unity project, which is an updated version of the first game I ever published online. Introducing....No Crooks On Christmas! I decided to upgrade No Crooks On Christmas as a kind of challenge to mys...

Level up your game development skills by learning to spot and fix these common Unity errors.

Learn the differences between a project name and a product name

It's the end of the first week of my first time as an official Hacktoberfest participant! There have been many ups and downs this week, and I thought I'd summarize them here so that others can see what the experience of a first-timer is like. So wit...

If you’re a developer, chances are you’ve used version control.
From Git to Mercurial, there are many version control systems to choose from. But have you ever wondered how these tools came to be?
In this article, I’ll be looking back at the history of version control and tracing its origins from a simple punched card system to the sophisticated software we know now.
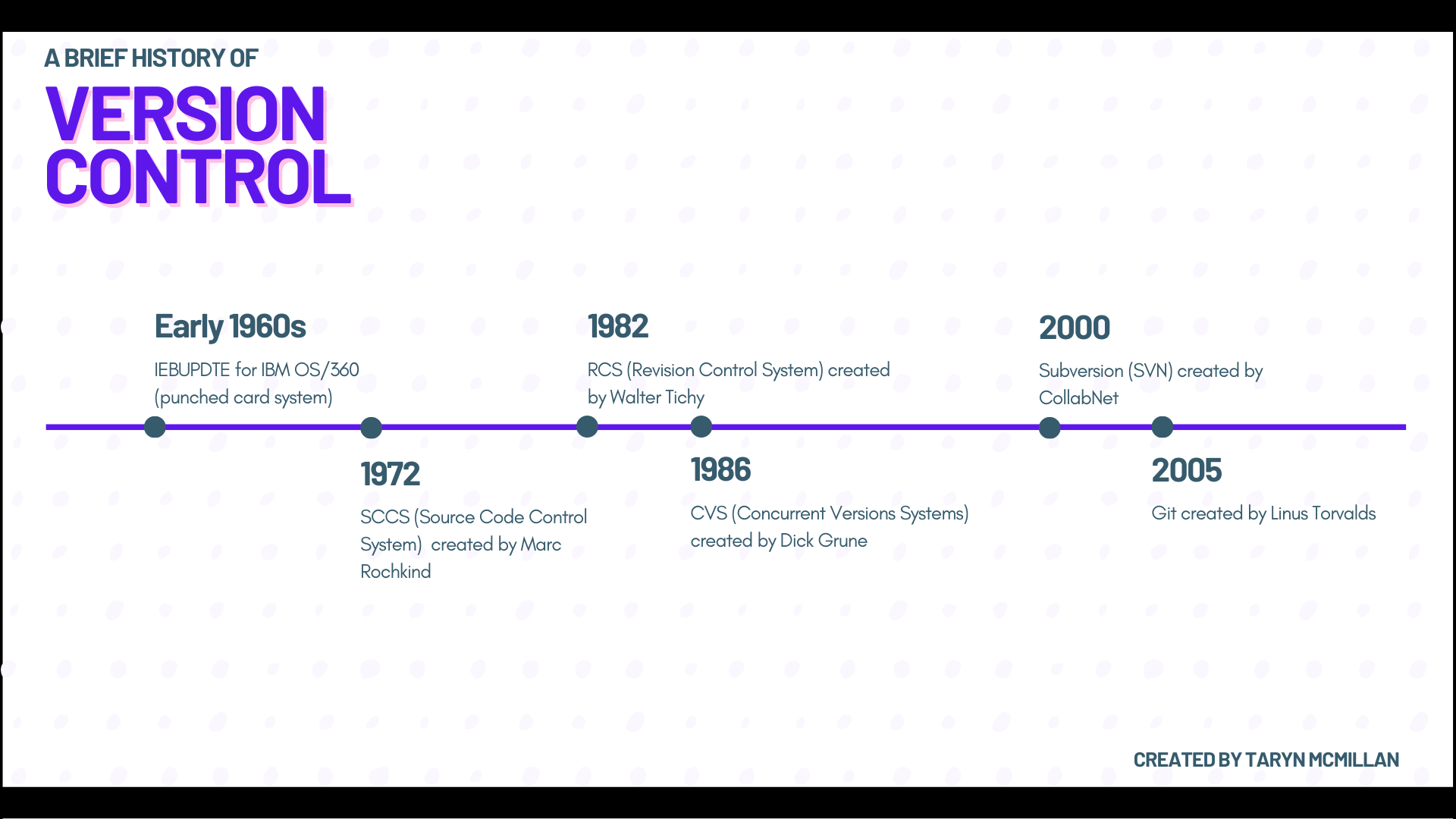 A timeline of version control systems from the early 1960s through the early 2000s
A timeline of version control systems from the early 1960s through the early 2000s
The predecessor of modern version control tools was IEBUPDTE, which was used with IBM's OS/360. It was developed in the early 1960s and primarily used punched cards to store data. While there is some debate over whether IEBUPDTE constitutes ‘true’ version control, it did provide the ability to create and update libraries of code in a way that’s similar to today’s patching systems.
In 1972, Bell Labs made a breakthrough in the field of version control. They created SCCS (Source Code Control System), which was written in C and developed by Marc Rochkind. This system shared many characteristics with modern version control systems such as the ability to create, edit, and track changes to files. However, it lacked the ability for more than one user to check out and work on a file at the same time. SCCS was made available to the public in 1977 and was the primary version control system into the early 1980s.
In 1982, Walter Tichy developed a new system called RCS, or Revision Control System. RCS still only allowed one user at a time to make edits and only supported the ability to work on single files, rather than a whole project. However, it did pioneer a new way of tracking changes called reverse deltas. Rather than store all of the versions of a file, RCS used a single recent version as its baseline from which all other versions were created. For the time, this was a faster and more efficient way of tracking changes.
A few years later in 1986, Dick Grune developed CVS (Concurrent Versions Systems), which was also written in C. CVS finally allowed more than one developer to work on a file at the same time. Users would deploy the UpdateVersion command to update a file to the latest version of that file on the server. CVS used delta encoding or compression, which tracks differences but not entire versions of files. With its use of a client-server model and branches, CVS is a much more modern example of version control.
The next major version control system was Subversion (SVN), which was created in 2000 by CollabNet. SVN preserved many of the features included in CVS so that users could easily transition between the two. By 2010, SVN was renamed Apache Subversion after it became part of the Apache Software Foundation.
SVN is an example of a centralized version control system (CVCS). Changes are made to a single copy of the project on a server and other users can pull down the latest version of the project to make their edits. There are many Subversion clients still in use today, such as Tortoise SVN and SmartSVN. However, CVCS has been eclipsed in recent years by a more modern form of version control: the distributed version control system (DVCS).
This brings us to the present. Currently, the most well-known DVCS is Git, which was created in 2005 by Linus Torvalds. The basic logic behind a DVCS is that a copy of the repository and its history is downloaded by every user. Systems like Git are known for being fast and reliable, with good branching capabilities. For now, it seems that DVCS is the future of version control, but as repositories continue to grow in size, it may be necessary to innovate even further.
By now I hope you can see that version control has a long and fascinating history. As developers, we sometimes take applications like Git for granted. The next time you use version control, take a moment to appreciate all of the hard work that went into making this essential everyday tool.
https://svnbook.red-bean.com/en/1.7/svn.intro.whatis.html#svn.intro.history
https://www.perforce.com/blog/vcs/what-svn
https://www.gnu.org/software/rcs/.
https://www.plasticscm.com/version-control-history
https://en.wikipedia.org/wiki/Version_control
https://www.red-gate.com/blog/database-devops/history-of-version-control
https://initialcommit.com/blog/Technical-Guide-VCS-Internals
https://softwareengineering.stackexchange.com/questions/184695/when-was-source-control-invented
https://www.perforce.com/blog/vcs/what-dvcs-anyway
https://en.wikipedia.org/wiki/Comparison_of_version-control_software#History_and_adoption
https://www.atlassian.com/blog/software-teams/version-control-centralized-dvcs
http://cap-lore.com/BigStore/RevDelta.html